We often see many methods for solving problems with ML being discussed here and there. But when it comes to getting all of the models actually going into production, we don’t see that much traction—and people still have to rely on a public cloud source or c. In this article, we will discuss the machine learning models that will be used in a production environment and the system architectures that support them. Let’s look at how you can do this without having to use a public cloud provider.
Model Export
Basically, all machine learning models are mathematical expressions, equations, or data structures (tree or graph). Mathematical expressions have coefficients, some variables, some constants, and some parameters of probability distributions (distribution-specific parameters, standard deviations, or mean).
Exporting a model is nothing more than writing the model’s metadata onto a file or data store. This is necessary to save the model for future use.
Exporting model independent of the platform
Machine learning models are trained using various technological glasses, such as Python, Java, .NET, etc. In Python, there are different frameworks, such as Sci-Kit-Learn, Pytorch, Tensorflow, and many others. There is an obvious need for the model to be independent of the platform.
In most cases, the typical use of models will be cross-platform. The model can be developed on the Python platform, but for high accessibility reasons, it can be served on the Java platform. We will discuss this in detail in the following sections. Before that, let’s discuss two different formats for the export of models.
PMMML: This is the language for marking forecast models. This is a standard based on XML, and it has a predetermined scheme. The model is exported as an XML file.
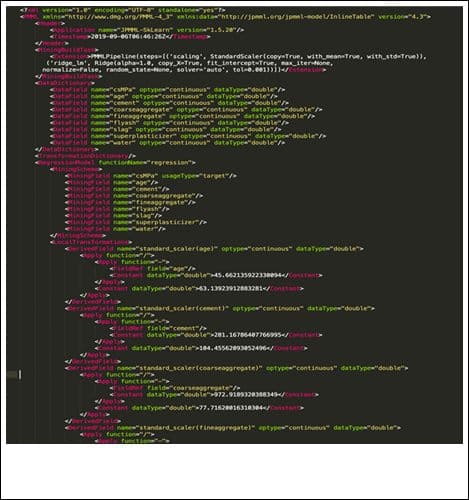
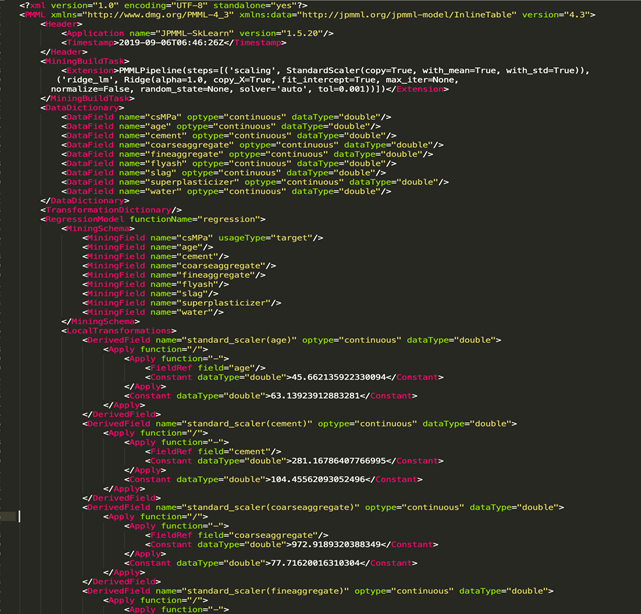{kind=link}
The above PMML content is for a linear regression model. We can see that it contains the model type (in the above case, regression), preprocessing steps (in the above case, StandardScaler), function names, and a lot of other information.
PMML suffers from size issues. Too many functions create rather large XML files, especially for NLP models. Therefore, it is sometimes convenient to convert PMML content to JSON.
ONNX: This is short for Open Neural Network Exchange. It is ideal for deep learning models. It creates a network graph that is serialized into a binary file. As usual, the graph contains information about the weights of the hidden and output layers and connections. Unlike PMML, it does not create XML.
Both of these formats are portable (especially PMML) across platforms.
Consumption and Portability of a Model
An exported model using the above formats can be used for actual use. Model training involves an iterative process of determining its parameters and hyperparameters. But after training, model consumption is a one-time process.
Let’s say we’ve trained a linear regression model using stochastic gradient descent on a high-performance machine. The generated model would beis a set of coefficients, function names, and preprocessing information. It needs to be saved somewhere in any format so that we can download and use it later.
To use the model, we simply need to multiply the features from the input data instance by the coefficients, add the intercept, and return the result.
Thus, it does not matter on which platform the model was developed and built. In machine learning-based production systems, it is natural that the developed components can be used from different MLOps platforms. With proper model export support, a model developed in Python can be used in an Android application.
In general, the logic for consuming a machine learning model should be developed inside the consuming platform. We can call it a stub.
The following diagram explains the situation.
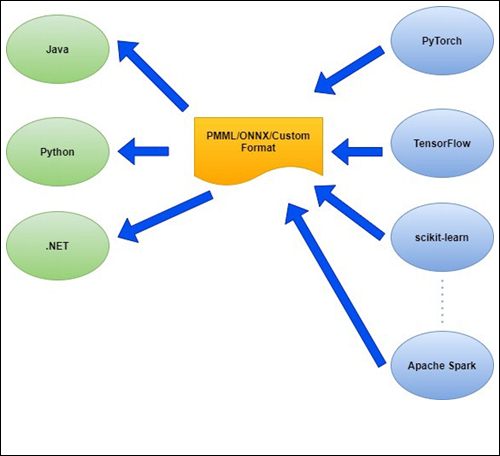
{kind=link}
The model developed in different Python frameworks (sci-kit-learn, PyTorch, TensorFlow) or big data stacks like Apache Spark/Flink can be exported in any given format (PMML/ONNX) and the same can be used by different client applications (Java, Python or .NET). So, this turns out to be a many-to-many situation.
Client applications parse the model file and extract the necessary parameters to build the in-memory version of the model.
Instead of relying on PMML/ONNX or any standard format, a custom format can also be defined for some very specific requirements (as shown in the diagram). In any case, the goal is to make the model portable to various platforms.
Model Deployment and System Architecture
Most data science activities are done in Python using the standard libraries described above. But, this is not a very scalable option. We need a solid data development and deployment platform for production-grade systems. This is where big data plays a big role. Models can be trained with petabytes of data on big data platforms like Spark, Hadoop, Flink, etc. In fact, they are always preferred in production systems.
There are two problems with architectural design. One issue related to Python has already been mentioned above. The other is with the big data platform itself.
Apache Spark/Flink are not suitable for synchronous integration and they work in stand-alone/batch/asynchronous modes.
So direct access to the Spark/Hadoop level prediction API via REST can be very dangerous for high/moderate throughput client systems. Even with low bandwidth requirements, synchronous integration is generally not recommended. Here, the problem is solved by a model export mechanism using PMML/ONNX or another format.
The model must be trained using a big data stack and then exported and stored in a model registry. It should support versioning and history mechanisms for the incremental/iterative learning processes. The flow is cyclical and is shown below:
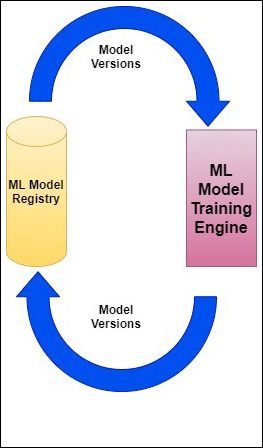
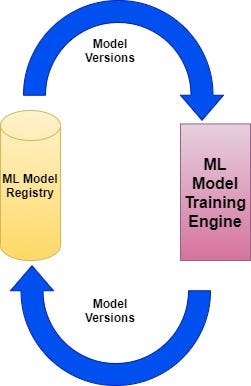{kind=link}
Then one prediction engine should use the model and return the result. This engine should be well versed in model export formats. Thus, the process of forecasting and learning becomes completely disconnected and loosely coupled.
Even in some hypothetical situations, if a model is trained with Python frameworks on small datasets instead of a large data stack, the prediction engine does not need to be updated. This is a big advantage of this type of design.
We will now discuss three different model deployment system architectures which use the concept described above.
On-demand Cloud Deployment (as a Service)
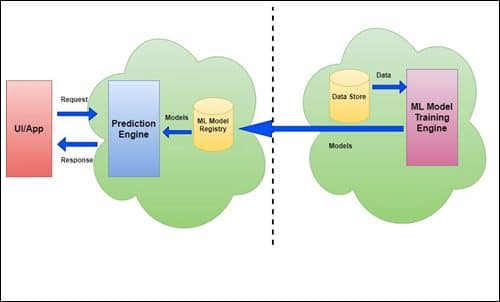
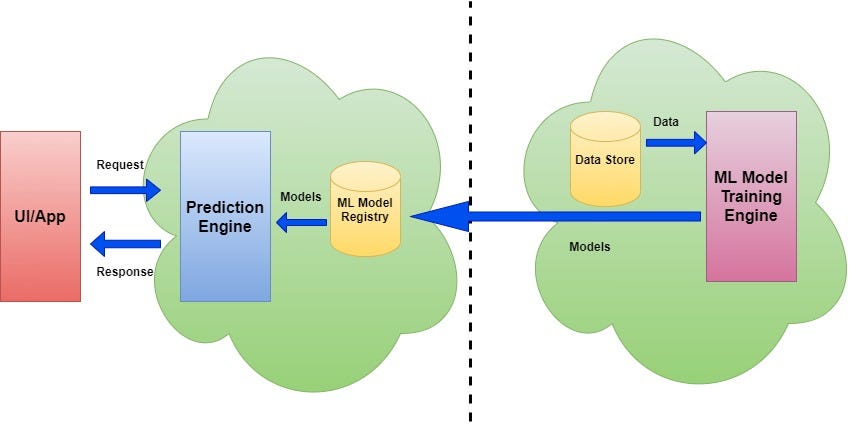{kind=link}
In the diagram above, we can see that the models are trained and placed into the model registry offline (the dotted line indicates the offline process). This learning is a periodic and asynchronous process. The prediction engine takes requests from the client UI/application and executes the model to get the results. This is a synchronous on-demand process and is not related to the model’s learning mechanism.
Models are hosted here as services (via REST API) and provide real-time predictions. Most public cloud machine learning providers follow this architecture.
Offline Cloud Deployment
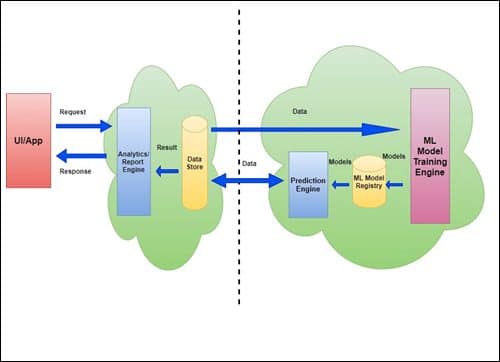
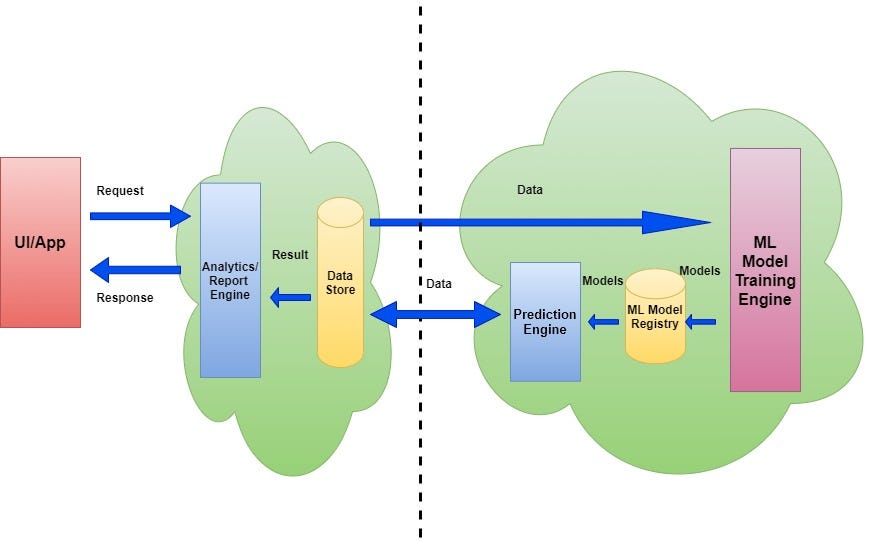{kind=link}
Here, the prediction engine works within the model training engine, and the prediction process also works offline along with training. Forecasts are stored in the data warehouse. One analytics engine handles synchronous requests from the UI/application and returns pre-stored predictions. Here, the model registry does not need to support all relevant model export formats since the predictions are made within the big data engine.
This architecture is useful in situations where models are used to generate an analysis report or set of recommendations offline.
Batch Deployment
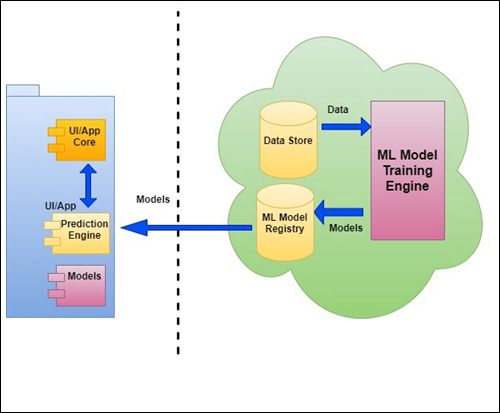
{kind=link}
Leave a Reply
You must be logged in to post a comment.